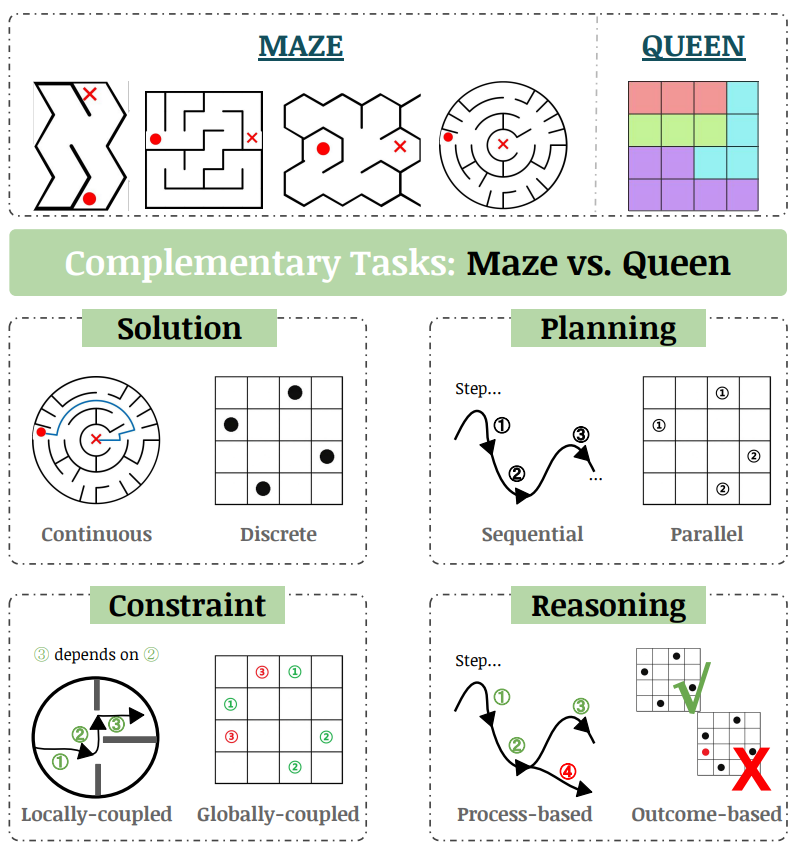
EAR asks an image editing model to transform an input puzzle image directly into a solved image. This avoids explicit step-by-step planning-by-generation and turns the whole planning process into one atomic visual edit.
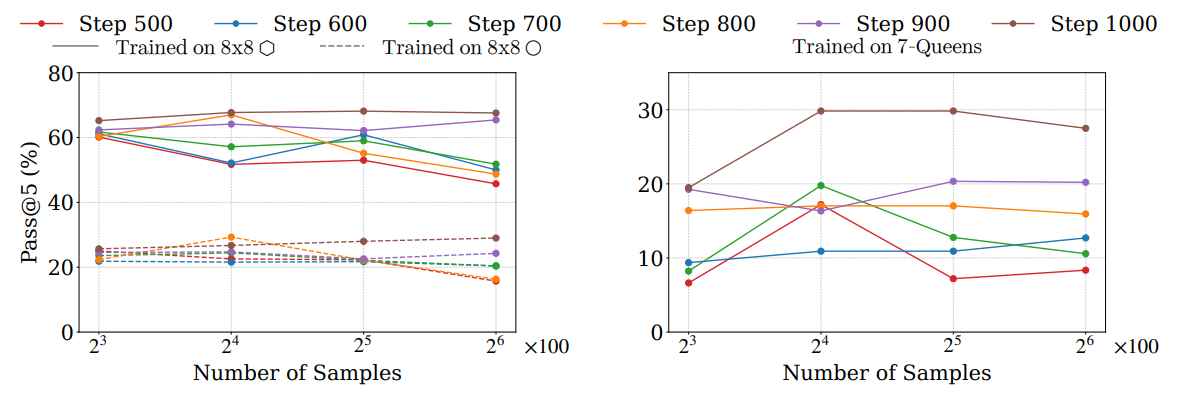
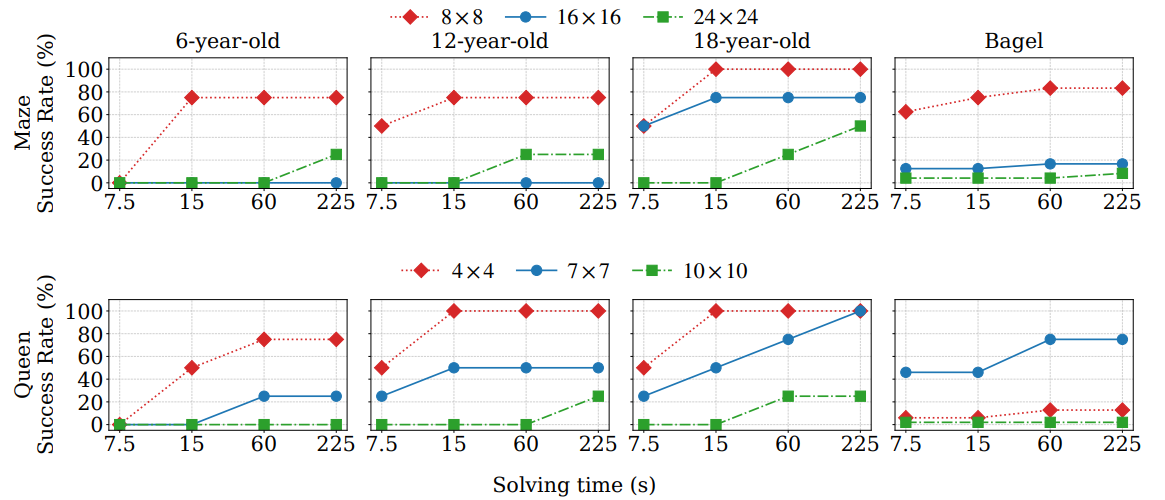
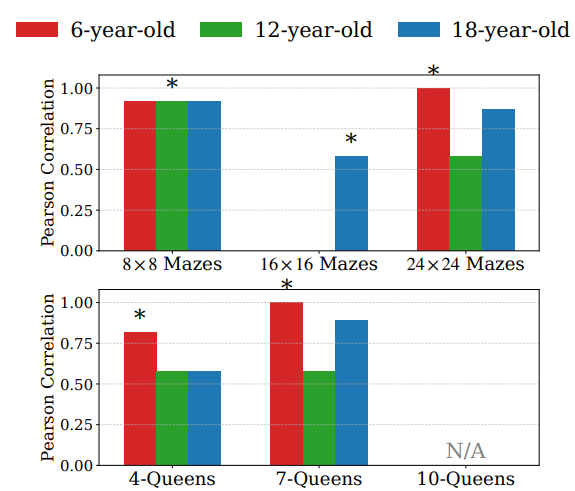
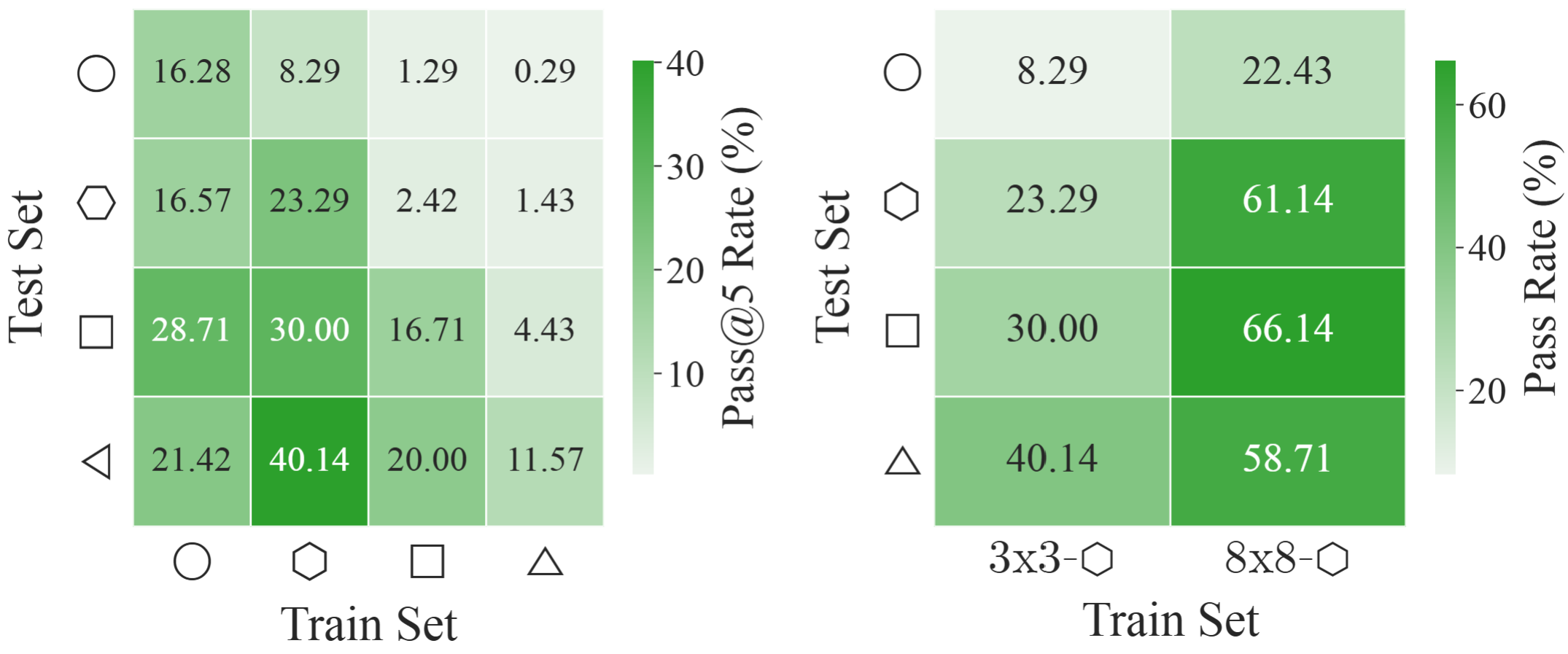
AMAZE supports automatic evaluation on both tasks. Logical validity is measured through Coverage, Violation, and Pass, while pixel-wise fidelity is measured using MSE-In and MSE-Out. The paper reports 98% agreement between the automatic logical metric and human judges.
EAR Automatic Evaluation Maze + Queen
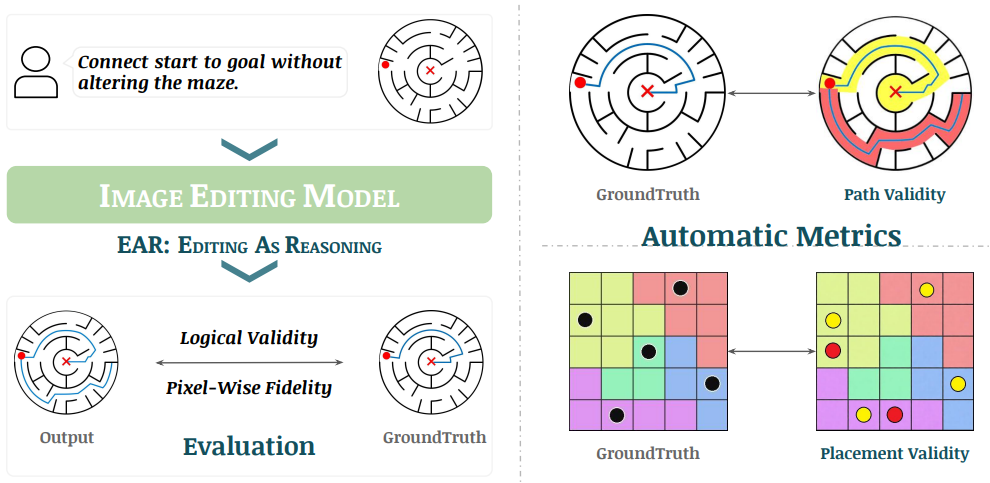
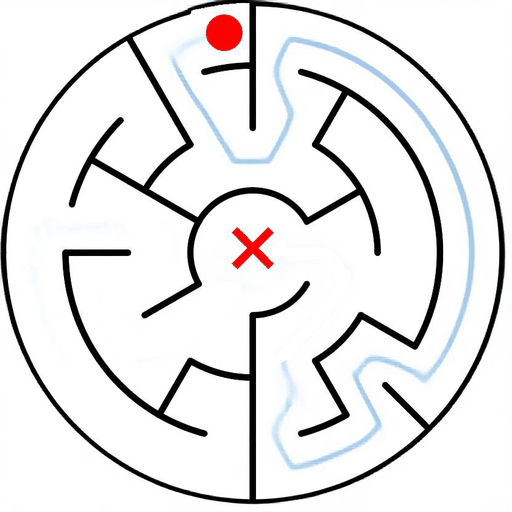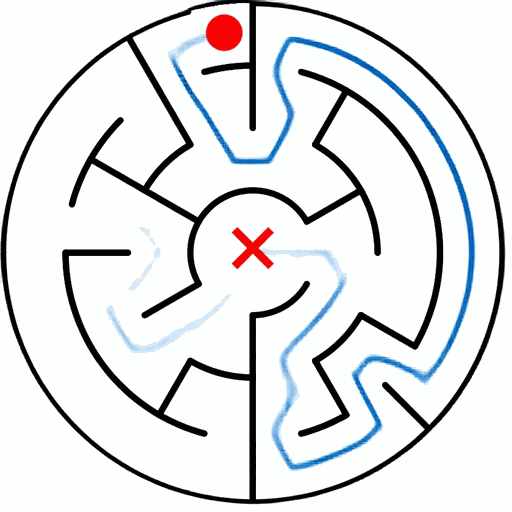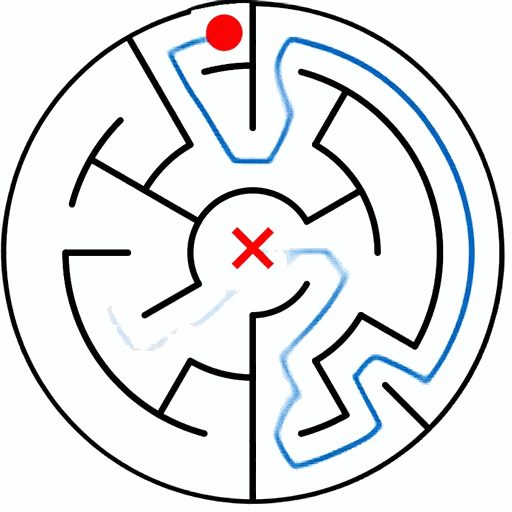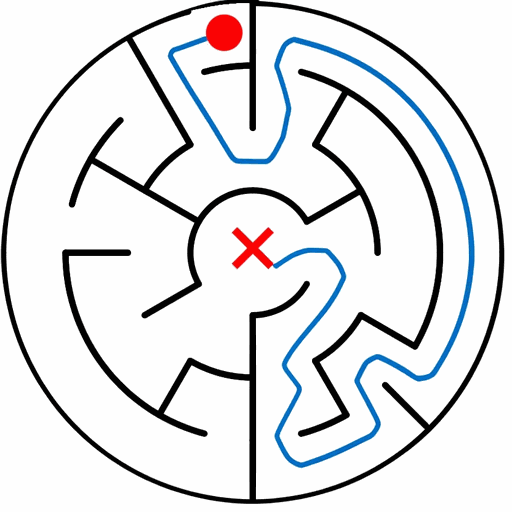
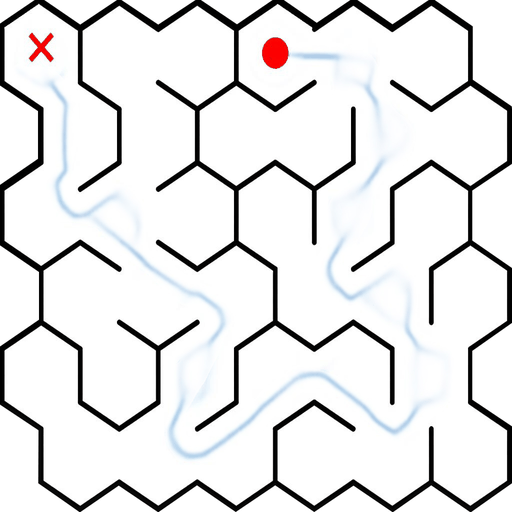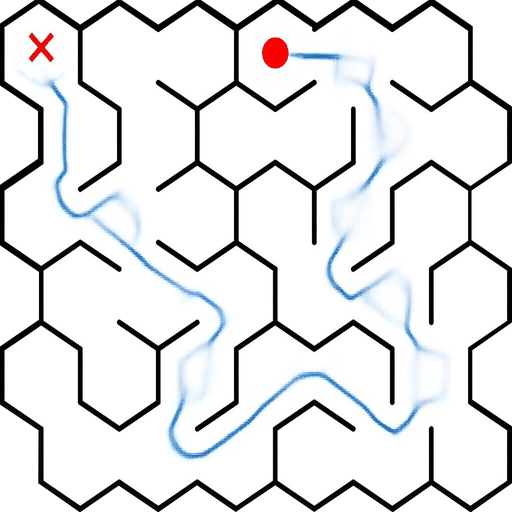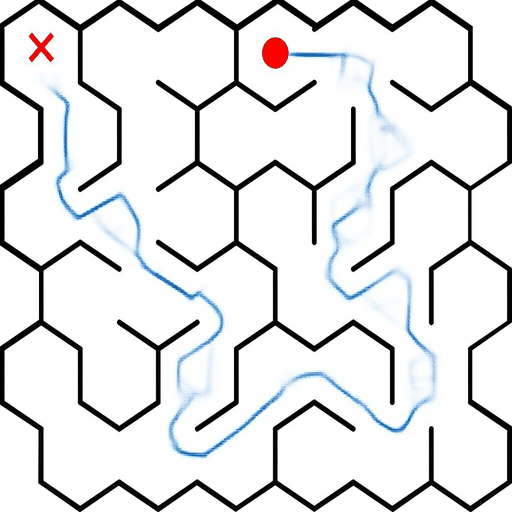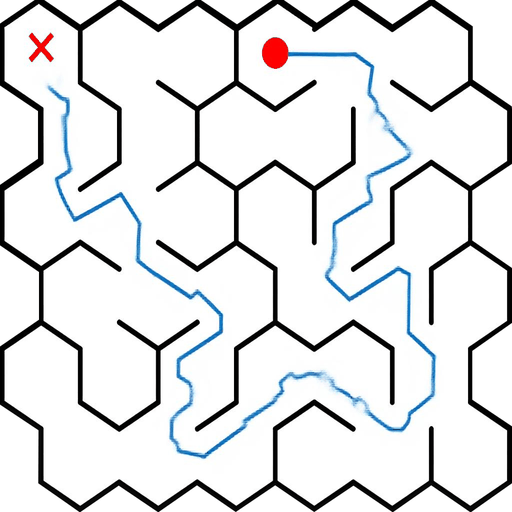
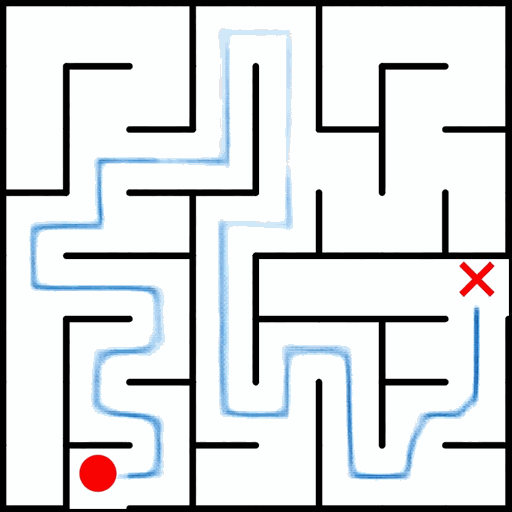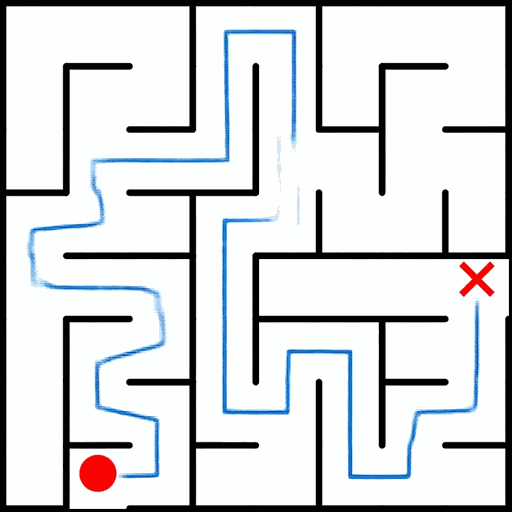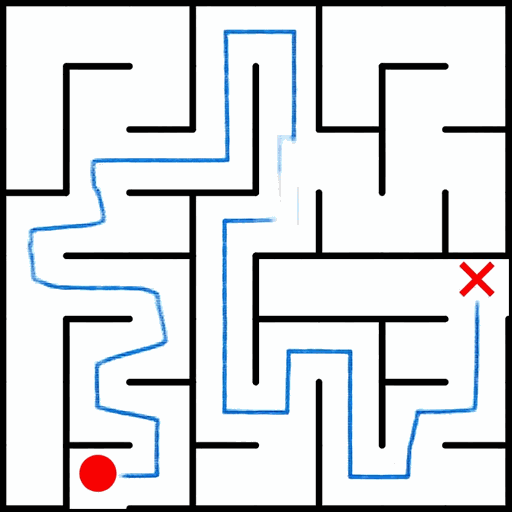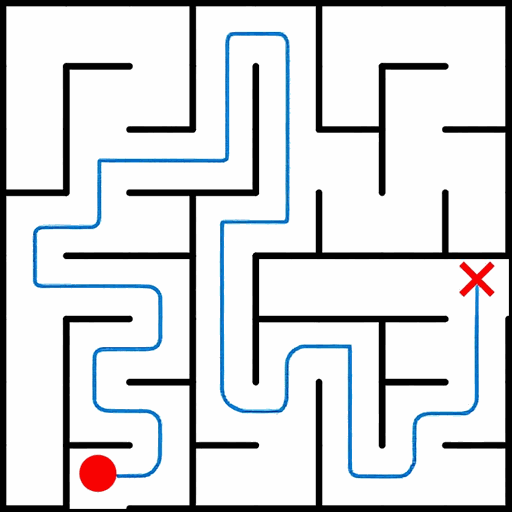
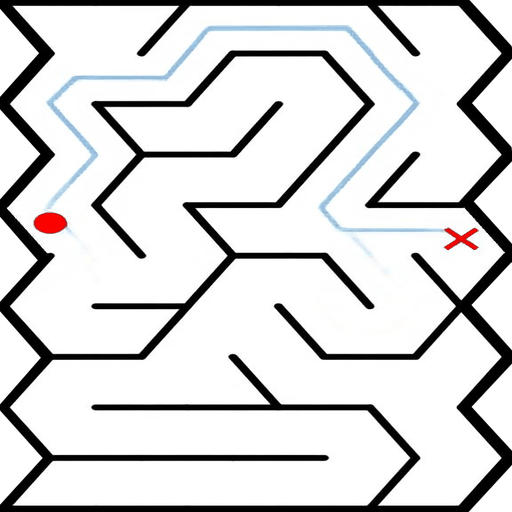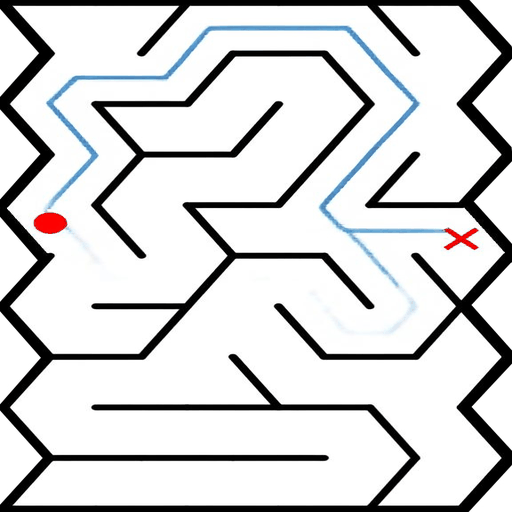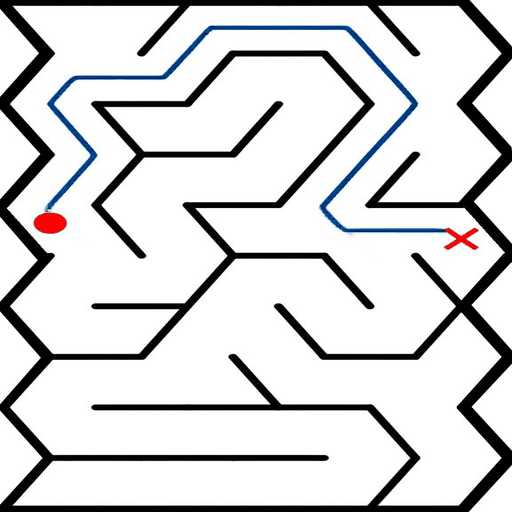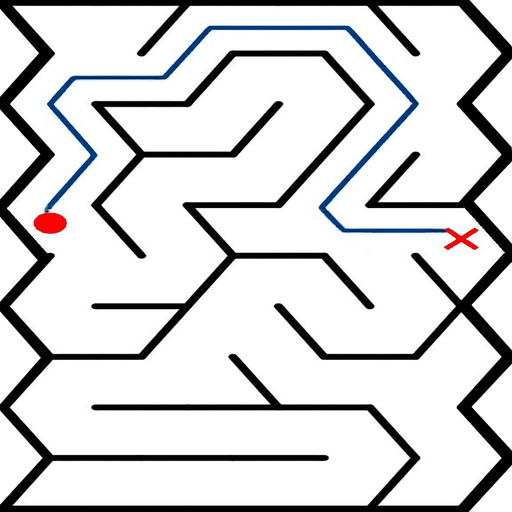

%20and%20Queen(bottom).png)